
Lucia: A Privacy-Preserving
Decentralized AI Assistant
Authors: Ing. Andreas Pensold, Ing. Josef Feiertag, David Heller, Farzan Naiemi, Joseph Akhras Release December 2024, Pindora FlexCo. Austria, hello@pindora.io
Abstract
The integration of artificial intelligence into daily digital communications has created unprecedented opportunities for efficiency and insight, yet it simultaneously raises critical concerns about privacy and data sovereignty. This paper introduces Lucia, a novel decentralized AI assistant that fundamentally reimagines how AI can process and analyze digital communications while maintaining robust privacy guarantees through advanced cryptographic techniques and secure computation frameworks. Lucia combines cutting-edge Privacy-Enhancing Technologies (PETs) with sophisticated retrieval and generation capabilities. The system employs Nillion's Blind Compute (NBC) technology, and Trusted Execution Environments (TEE) to ensure data remains protected throughout its lifecycle. By processing information within a secure private cloud infrastructure and leveraging advanced vector database technology, Lucia delivers sophisticated AI capabilities including real-time summarization, trend analysis, and cross-platform insights while maintaining strict privacy guarantees. Keywords: AI Agents, Large Language Models, Vector Database Integration, Retrieval Augmented Generation, Decentralization, Trusted Execution Environments, Multi Party Computation, Blockchain
Introduction
1.1 Information Overflow
The proliferation of digital communication platforms has transformed how individuals and organizations interact, leading to an unprecedented volume of information flow across multiple channels. This transformation, while enabling greater connectivity and collaboration, has created significant challenges in information management and privacy preservation. Users increasingly find themselves navigating complex networks of communication platforms, each generating continuous streams of updates, notifications, and messages that demand attention and processing. AI agents offer the unique opportunity to process this flood of data in real time to provide only relevant, pre-filtered information while processing automated tasks in the background on behalf of the users.
1.2 The Privacy Challenge in AI Systems
The rapid advancement of artificial intelligence, particularly large language models (LLMs), has transformed how we process and understand information. However, this transformation brings significant challenges regarding privacy, data sovereignty, and security. Traditional AI systems typically rely on centralized architectures that create inherent vulnerabilities: First, centralized systems require users to surrender control over their personal and professional communications to third-party providers. This loss of data sovereignty raises concerns about how sensitive information might be used or accessed without user knowledge or consent. Second, the consolidation of data in central repositories creates attractive targets for malicious actors. A successful breach of these systems could expose vast amounts of sensitive information, making them particularly vulnerable to sophisticated attacks. Third, users must place implicit trust in platform operators to handle their data responsibly. This trust requirement becomes increasingly problematic as organizations face growing pressure to improve training data for their next generation LLM’s, monetize user data to satisfy shareholders expectations or comply with various governmental requests for information access. Finally, evolving privacy regulations like GDPR and CCPA impose strict requirements on how personal data can be processed and stored. Centralized systems often struggle to comply with these regulations while maintaining full functionality.
1.3 The Need for a New Approach
These challenges demand a fundamental rethinking of how AI systems process and analyze digital communications. Any viable solution must address several key requirements:
1
Privacy Preservation
The system must ensure that user data remains protected throughout its entire lifecycle, from initial collection through processing and storage. This protection should extend beyond simple encryption to include guarantees about how data can be processed and accessed.
2
Decentralized Processing
To eliminate single points of failure and control, the system should distribute processing across multiple independent nodes. This distribution must maintain security and efficiency while preventing any single entity from gaining complete access to user data.
1
Platform Integration
The solution must work seamlessly with existing communication tools, applications and platforms. Users should not need to dramatically change their workflows or adopt entirely new systems to benefit from privacy-preserving AI capabilities.
2
User Empowerment
Control over data and processing should remain firmly in users' hands. This includes fine-grained permissions for data access, processing parameters, and integration configurations.
1.4 Lucia: A Privacy-First AI Assistant
Lucia addresses these challenges through a novel architecture that combines several cutting-edge technologies: First, it employs Nillion's Blind Compute (NBC) technology to enable secure computation on fragmented data. This approach ensures that sensitive information remains protected even during processing, as no single entity ever has access to complete data. Second, Lucia implements sophisticated encrypted vector database technology to enable efficient retrieval and processing of information while maintaining privacy guarantees. This allows the system to provide advanced AI capabilities without compromising security. Third, the system leverages Trusted Execution Environments (TEEs) on modern GPUs to ensure secure model inference and data processing. This hardware-backed security adds an additional layer of protection for sensitive computations on systems hosted by third parties. Finally, Lucia implements a comprehensive privacy-preserving retrieval-augmented generation (RAG) system that enables AI capabilities to be enhanced with external knowledge while maintaining strict privacy controls. This paper details how these technologies work together to create a secure, efficient, and privacy-preserving AI assistant. We begin by examining the system's core architecture, then explore each major component in detail, and finally discuss performance characteristics and future directions.
System Architecture
2.1 Architectural Overview
Lucia's architecture represents a fundamental departure from traditional centralized AI systems. Instead of consolidating data and processing in a single location, Lucia distributes both across a network of secure nodes while maintaining strict privacy guarantees. This distributed approach provides several key advantages: First, it eliminates single points of failure that could compromise user privacy. By distributing data and processing across multiple nodes, the system ensures that no single breach can expose significant amounts of sensitive information. Second, it enables sophisticated privacy-preserving computation through technologies like MPC and TEEs. These technologies allow AI processing to occur without ever exposing the underlying data in an unprotected form. Third, it provides natural scalability as additional nodes can be added to the network to handle increased processing requirements while maintaining security guarantees.
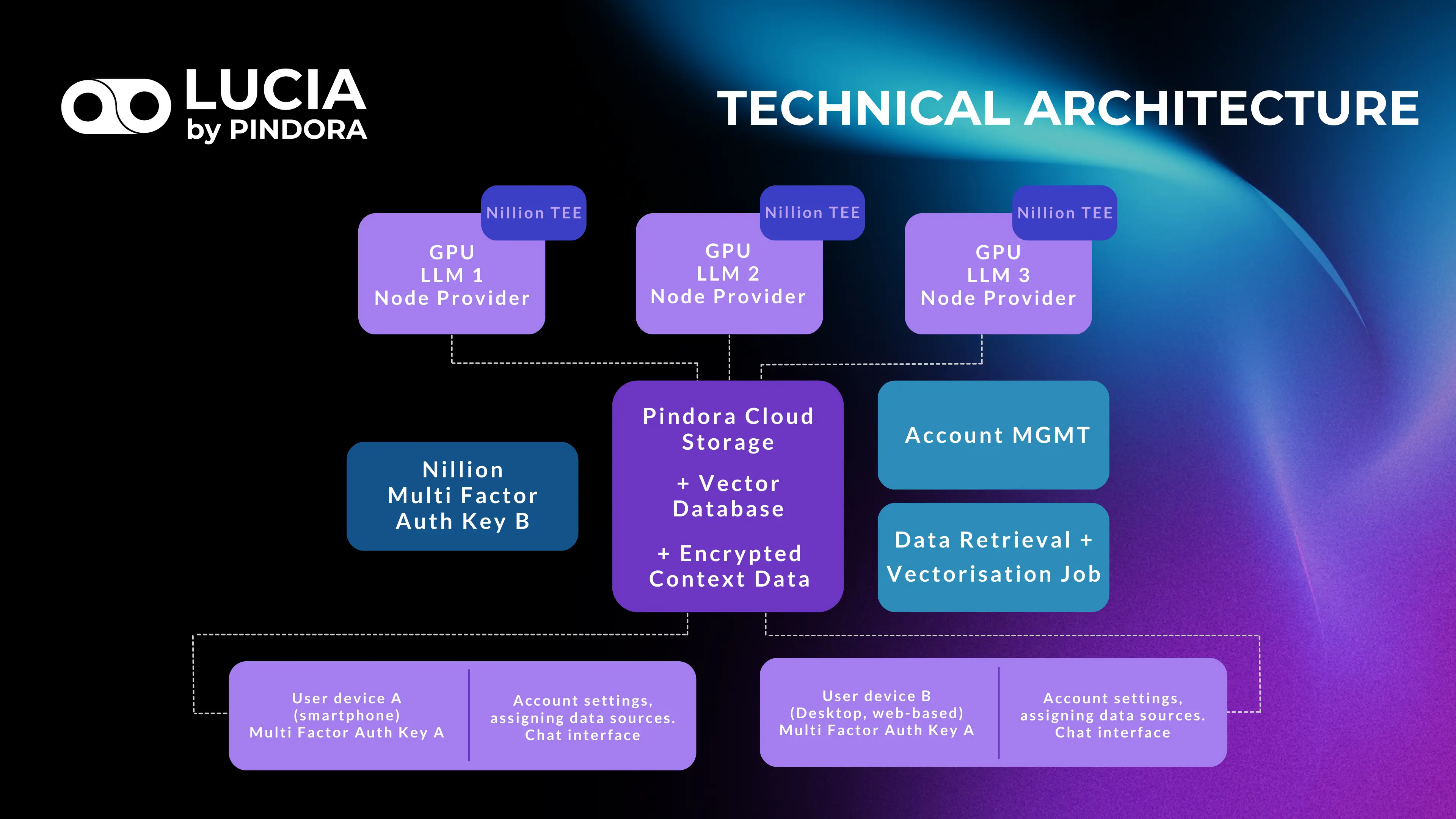
Figure 1: Architecture Overview
2.2 Core Components
At the core of Lucia's privacy-preserving capabilities lies Nillion's Blind Compute Network (NBC), which offers novel cryptographic primitives that fundamentally reimagines secure computation and authentication. NBC enables unprecedented, quantum-proof security in distributed computing environments while maintaining strict privacy guarantees. Pindora is a member of the first cohort of the Nillion Nucleus Builders Program. Lucia's architecture consists of several key components that work together to provide secure, efficient AI capabilities:
User Interface via Smartphone App / Web Application
Secure Decentralized Multi-factor Authentication
Retrieval Augmented Generation
Decentralized Cloud Storage Infrastructure
Privacy-Preserving GPU Inference
2.2.1 User Interface
The primary component of the user interface is the Lucia AI App, which will be accessible as a mobile application for both Android and iOS platforms, as well as a native web-based interface for desktop users. Upon account creation, users have the capability to integrate various data sources, including local files and messenger accounts.
2.2.2 Authentication and Access Control
A comprehensive security framework ensures that only authorized entities can access specific data and capabilities. This includes decentralized multi-factor authentication and fine-grained permission management through Nillion’s Blind Compute Network (NBC). This foundation enables privacy-preserving processing through Nillion’s Multi Party Computation (MPC). Nillion fragments sensitive data and distributes processing across multiple nodes while ensuring that no single node can access complete information. The operational framework of MPC represents a fundamental advancement in privacy-preserving computation. At its core, Nillion’s blind compute network employs sophisticated mathematical principles to enable computation on fragmented data while maintaining strong security guarantees.
2.2.3 Privacy-Preserving RAG System
This layer enables AI capabilities to be enhanced with external knowledge from various information channels (e.g. local files, emails, messages, social accounts, etc.) while maintaining strict privacy controls. It implements sophisticated retrieval and generation mechanisms that operate on private data
2.2.4 Decentralized Cloud Vector Database Infrastructure
A sophisticated distributed database system enables efficient storage and retrieval of vector representations while maintaining privacy guarantees. This
2.2.5 Trusted Execution Environment for Inference
Lucia leverages state-of-the-art GPU-based Trusted Execution Environments (TEEs) to ensure secure AI model inference while maintaining high performance. The local TEE integration for the GPU node environment is realised with Nillion’s PET orchestration layer.
Infinite Memory Architecture
3.1 The Memory Challenge in AI Systems
Traditional large language models face a fundamental limitation that restricts their ability to maintain long-term context: they operate within fixed context windows that determine how much information they can process at once. This limitation arises from both architectural constraints and computational requirements. When these models process conversations or documents, they can only "see" a certain amount of text at a time, typically ranging from a few thousand to a few hundred thousand tokens. Everything beyond this window becomes inaccessible, leading to what we might call "artificial amnesia." This limitation creates several significant challenges. First, models struggle to maintain consistency in long conversations because they cannot reference earlier interactions that fall outside their context window. Second, they cannot build upon accumulated knowledge from previous conversations, forcing users to repeatedly provide the same context. Third, they cannot develop genuine long-term relationships with users, as each interaction essentially starts fresh once previous context falls outside the window.
3.2 Lucia's Infinite Memory Solution
Lucia implements a revolutionary approach to memory that transcends these limitations through a sophisticated combination of vector database technology and privacy-preserving computation. Instead of relying solely on a fixed context window, Lucia maintains a continuous, privacy-protected memory that spans the entire history of interactions with each user.
3.3 Architectural Implementation
The infinite memory architecture consists of several sophisticated components working in concert:
Secure vector storage implements a privacy-preserving system for maintaining conversation history:
Chat conversations are fed back into the vector database via a dedicated RAG pipeline
The vector database is fully encrypted via MFA and requires the local user key + the key stored on the Nillion network to access the personal data repository
Sophisticated indexing enables rapid retrieval of relevant information
RAG memory embedding system transforms conversations into rich semantic representations:
Advanced embedding models capture nuanced meaning and context
Temporal relationships are preserved through sophisticated timestamping
Cross-reference mechanisms maintain links between related conversations
Hierarchical organization enables efficient navigation of memory space
Context Management implements intelligent memory access:
Automatic prioritization of important information
Efficient handling of redundant or outdated information
Privacy-preserving memory consolidation
Dynamic context selection based on query relevance
3.4 Persistent Context Understanding
The system maintains deep understanding across extended timeframes:
Historical Context Integration enables:
Recognition of recurring themes and topics
Understanding of evolving user preferences
Maintenance of consistent interaction patterns
Long-term goal tracking and progress monitoring
Relationship Memory maintains:
User interaction history and preferences
Communication style adaptations
Shared knowledge and references
Trust building through consistent engagement
3.5 Knowledge Accumulation
Lucia’s infinite memory architecture implements mechanisms for building and maintaining a user-focused knowledge base:
Progressive Learning enables:
Accumulation of user-specific information
Development of specialized domain knowledge
Recognition of evolving patterns and preferences
Adaptive response refinement
Information Synthesis maintains:
Cross-conversation knowledge integration
Contradiction detection and resolution
Updates to outdated information
Context-aware information presentation
3.6 Use-Cases for Long-Term Assistance
Lucia’s extended memory capabilities provide sophisticated long-term support:
Project Management:
Maintaining project context over extended periods
Tracking progress against long-term goals
Preserving decision rationales and historical context
Ensuring consistency in long-running projects
Knowledge Work:
Building comprehensive domain expertise
Maintaining research context and progress
Supporting iterative development processes
Enabling sophisticated knowledge synthesis
3.7 Use-Cases for Relationship Development
Lucia can build and maintain meaningful long-term relationships:
Personal Assistance:
Remembering personal preferences and history
Maintaining conversation context over time
Supporting goal progress and personal development
Providing consistent, personalized interaction
Virtual friendship and support for everyday problems
Motivational coaching and personal trainer
Tutoring to learn new skills
Professional Support:
Maintaining business context and relationships
Supporting long-term professional development
Enabling sophisticated collaboration
Preserving organizational knowledge
Business strategy development
Autonomous research assistant
3.8 Future Implications
Lucia's infinite memory architecture opens several exciting possibilities for future development:
Advanced Learning enables:
Continuous knowledge accumulation
Adaptive behavior refinement
Sophisticated pattern recognition
Enhanced predictive capabilities
Enhanced Interaction allows:
Deep relationship building
Sophisticated context awareness
Advanced personalization
Improved understanding over time
These capabilities fundamentally transform how AI systems can interact with users, enabling truly long-term relationships and sophisticated support that was previously impossible with traditional LLM architectures.
Retrieval-Augmented Generation Architecture
4.1 Evolution of RAG Systems
The development of Retrieval-Augmented Generation (RAG) represents a fundamental advancement in how AI systems access and utilize knowledge. Traditional language models, while powerful, often struggle with limitations in their pre-trained knowledge. These limitations become particularly apparent when dealing with domain-specific information, personal data or recent developments not included in their training data. The evolution of RAG systems has progressed through several distinct paradigms, each addressing specific challenges and limitations of its predecessors. Understanding this evolution provides crucial context for Lucia's implementation choices.
4.2 Naive RAG Implementation
The initial RAG implementations followed a straightforward approach that, while groundbreaking, had several limitations. In these systems, the process flow moves linearly from query to response: First, the system indexes documents by converting them into vector representations through an embedding model. When a user submits a query, the system transforms it into a similar vector representation and retrieves relevant documents based on similarity measurements. These documents, combined with the original query, form a prompt for the language model to generate a response. While this approach improved upon basic language models, it faced several challenges. The retrieval process often struggled with precision, sometimes selecting misaligned or irrelevant information. The generation phase could produce hallucinations when the retrieved context wasn't perfectly aligned with the query. Additionally, the system sometimes struggled with redundancy in retrieved information
4.3 Advanced RAG Architecture
To address the limitations of naive implementations, advanced RAG systems introduced sophisticated pre- and post-retrieval optimizations. These systems implement multiple strategies to enhance retrieval quality and response generation. In the pre-retrieval phase, the system optimizes both the indexing structure and the original query. Indexing optimization focuses on enhancing content quality through strategies like improved data granularity and metadata enrichment. Query optimization employs techniques such as query rewriting and expansion to improve retrieval accuracy. Post-retrieval processing introduces additional refinements. The system reranks retrieved chunks to prioritize the most relevant information and implements context compression to manage information density effectively. These enhancements significantly improve the quality and relevance of the generated responses.
4.4 Modular RAG Framework
The most sophisticated RAG implementation, which Lucia adopts, employs a modular architecture that dramatically improves flexibility and capability. This approach introduces specialized modules that can be combined and reconfigured to handle different types of queries and data sources optimally. The modular framework includes several key components:
1
Search Module:
This component adapts to specific scenarios, enabling direct searches across various data sources including search engines, databases, and knowledge graphs. It can generate and execute specialized queries in multiple query languages
2
Memory Module
By leveraging the language model's memory capabilities, this module creates an unbounded memory pool that helps align text more closely with data distribution through iterative self-enhancement. It maintains context across interactions and improves response coherence.
1
Routing Module:
This component intelligently directs queries through the most appropriate processing pathway, whether that involves summarization, specific database searches, or the integration of multiple information streams.
2
Task Adapter Module:
Specialized components adapt the system's behavior for various downstream tasks, automating prompt retrieval for zero-shot inputs and creating task-specific retrievers through few-shot query generation.
4.5 Implementation Patterns
Lucia implements several sophisticated patterns within its modular RAG framework to optimize performance for different types of queries and data sources.
4.5.1 Rewrite-Retrieve-Read Pattern
This pattern enhances query processing through a three-stage approach: First, the system employs the language model to refine and optimize the initial query, improving its ability to retrieve relevant information. The refined query then drives the retrieval process, which selects appropriate documents from the knowledge base. Finally, the system processes the retrieved information along with the original query to generate a response. This pattern incorporates a feedback mechanism where the language model's understanding of the retrieved content influences future query refinements, creating a self-improving cycle.
4.5.2 Generate-Read Pattern
In scenarios where direct retrieval might not yield optimal results, the system employs a generate-read pattern. This approach first uses the language model to generate hypothetical responses or context, which then guide the retrieval process. This method proves particularly effective when dealing with complex or abstract queries where direct keyword matching might fail.
4.5.3 Iterative Retrieval Pattern
Complex queries often benefit from an iterative approach where the system performs multiple rounds of retrieval and refinement. Each iteration builds upon the context and understanding developed in previous rounds, gradually constructing a more complete and accurate response. The system implements sophisticated stopping criteria to determine when sufficient context has been gathered, balancing comprehensiveness with efficiency.
4.6 Advanced Features
4.6.1 Cross-Modal Processing
Lucia extends traditional RAG capabilities to handle multiple modalities of information. The system can process and integrate:
1
Text Data:
Handles various formats including documents, conversations, and structured text from various sources.
2
Image Data:
Processes visual information through specialized embedding models and integration techniques.
3
Audio Data:
Converts speech to text and integrates it with other modalities for comprehensive understanding.
4.7 Retrieval Optimization
The RAG system implements several advanced retrieval optimization techniques:
1
Query Expansion:
Automatically generates multiple variations of queries to capture different aspects of the information needed.
2
Hybrid Search:
Combines semantic, keyword, and vector-based search methods for optimal retrieval
3
Dynamic Reranking
Adjusts result ordering based on context and user interaction patterns.
4.8 Response Generation
Response generation incorporates sophisticated mechanisms for ensuring quality and relevance:
1
Source Attribution:
Source Attribution:
2
Confidence Scoring:
Evaluates the reliability of generated responses based on retrieval quality and model confidence.
3
Style Adaptation:
Adjusts response format and style based on user preferences and query context.
4.9 Performance Optimization
The RAG system implements several strategies to optimize performance:
4.9.1 Caching Mechanisms
Intelligent caching of both retrieved documents and generated responses reduces latency for similar queries. The system implements:
1
Vector Caching:
Stores frequently accessed embeddings for rapid retrieval
2
Response Caching:
Maintains a cache of generated responses for common queries.
3
Context Caching:
Preserves relevant context across related queries in a session.
4.10 Parallel Processing
The system leverages parallel processing capabilities:
1
Concurrent Retrieval:
Executes multiple retrieval operations simultaneously across different data sources
2
Parallel Query Processing:
Processes multiple query variations concurrently for improved response time
4.11 Resource Management
Sophisticated resource management ensures optimal performance under varying loads:
1
Dynamic Allocation:
Adjusts computational resources based on query complexity and system load
2
Load Balancing:
Distributes processing across available resources for optimal throughput.
3
Priority Scheduling:
Manages query processing based on importance and urgency.
Vector Database Architecture and Implementation
5.1 Introduction
The emergence of artificial intelligence has fundamentally transformed how we think about information storage and retrieval. Traditional database systems, designed for exact matching and structured queries, prove insufficient for modern AI applications that require semantic understanding and similarity-based retrieval. This limitation has given rise to vector databases, which represent a paradigm shift in database architecture.
5.2 Vector Generation Layer
The foundation of any vector database system lies in its ability to generate meaningful vector representations. Relevant are several crucial components:
5.2.1 Sliding Window Processing
Lucia’s vector generation implements an overlapping window approach to maintain contextual continuity. This technique preserves semantic relationships across document boundaries by ensuring that each segment maintains awareness of its surrounding context. For instance, when processing technical documentation, each section's embedding reflects both its specific content and its relationship to adjacent sections.
5.2.2 Hierarchical Embedding
The system generates embeddings at multiple granularities, creating a rich representational hierarchy. This approach enables:
Sentence-level embeddings for fine-grained similarity matching
Paragraph-level embeddings for intermediate context
Document-level embeddings for broad topical relationships
5.3 Security Implementation
5.3.1 Data Isolation and Compartmentalization
Lucia's vector database implements strict data isolation through several mechanisms:
Secure key management infrastructure based on Nillion’s MPC network protects encryption keys with Multi Factor Authentication (MFA)
Separate encryption keys for different data categories
Isolated processing environments for sensitive operations
Granular access controls at the vector level
5.3.2 Secure Multi-Tenant Architecture
The architecture supports multiple users while maintaining data separation through:
Tenant-specific encryption keys
Isolated index partitions
Separate processing queues for different tenants
5.4 Graph-Based Indexing
Our implementation enhances the Hierarchical Navigable Small World (HNSW) algorithm through several innovative modifications:
5.4.1 Dynamic Graph Optimization
The system continuously refines the graph structure based on:
Observed query patterns
Emerging similarity relationships
Access frequency distributions
5.4.2 Multi-Layer Navigation
The index maintains multiple interconnected layers that enable efficient similarity search:
Upper layers provide broad similarity relationships
Lower layers enable precise matching
Layer transitions optimize search paths dynamically
5.5 Privacy-Preserving Search Implementation
The system implements several sophisticated mechanisms to ensure privacy during similarity search:
5.5.1 Encrypted Query Processing
All search operations occur within secure enclaves, ensuring:
Query vectors remain encrypted throughout processing
Intermediate results maintain encryption
Result decryption occurs only within authorized contexts
5.6 Performance Optimization
The system implements a multi-level caching strategy:
5.6.1 Vector Cache
A sophisticated caching system maintains:
Frequently accessed vectors in secure memory
Partial index structures for common search patterns
Encrypted result sets for repeated queries
Data Sovereignty and Platform Independence
The landscape of AI agents reveals a concerning trend where major providers implement what we might call "memory handcuffs" – strategies that make it difficult or impossible for users to transfer their conversation history and accumulated knowledge to different platforms. This approach to user lock-in creates several significant problems that affect both individuals and organizations.
6.1 The Lock-in Problem in Current AI Platforms
Traditional AI platforms typically implement closed ecosystems where user data and conversation history become effectively trapped within their ecosystems. Consider how this works in practice: When a user engages with these platforms over time, they build up a valuable history of interactions, preferences, and specialized knowledge. This history becomes a form of cognitive capital – representing hours of training the AI to understand specific needs, preferences, and context. However, these platforms typically store this valuable history in proprietary formats and closed systems. If a user wants to switch to a different AI provider, perhaps one that offers better privacy guarantees or more sophisticated capabilities, they face a difficult choice: either abandon their entire conversation history and start fresh, or remain locked into their current platform regardless of its limitations. This creates several problems: First, it artificially restricts user choice by making the cost of switching platforms prohibitively high in terms of lost context and training time. A user who has spent months or years building up context with one AI assistant effectively becomes tethered to that platform, even if better alternatives emerge. Second, it creates concerning privacy implications as users have limited control over how their conversation history is stored, used, or potentially monetized by the platform provider. The provider maintains complete control over this valuable personal or organizational data. Third, it stifles innovation in the AI assistant market by creating artificial barriers to competition. New platforms face significant challenges in attracting users, not because their technology is inferior, but because users are effectively locked into existing platforms through their accumulated conversation history.
6.2 Lucia's Approach to Data Sovereignty
Lucia fundamentally reimagines this relationship between users and their AI interaction history through what we call "portable memory architecture." This approach ensures that users maintain complete ownership and control over their conversation history and accumulated knowledge. The implementation of user-controlled private knowledge bases with flexible LLM integration represents a significant step toward more democratic and user-centric AI systems. Lucia's approach to data ownership creates several significant advantages:
User Empowerment:
Complete control over conversation history
Freedom to choose and switch platforms and AI Models
Privacy-preserving data management
Genuine ownership of accumulated knowledge
Technical Advantages:
Platform-independent secure data storage
Flexible integration capabilities
Enhanced privacy protection
Improved data security
Market Benefits:
Increased competition in AI services
Reduced barriers to innovation
Better alignment of provider incentives
Enhanced user choice
These capabilities fundamentally transform the relationship between users and AI platforms, enabling genuine choice while preserving the value of accumulated interaction history. By ensuring users maintain ownership of their data, Lucia creates a more equitable and innovative ecosystem for AI assistance in future.
6.3 Private Communication Acces
The integration of private communication channels represents a significant evolution in personal AI assistance. Unlike traditional AI systems that operate on limited, specifically provided data, Lucia can access, process, and derive insights from users' entire communication history across various platforms. This capability introduces new possibilities for personal assistance while raising important considerations about privacy, security, and user autonomy. Personal AI agents with access to private communications develop a sophisticated understanding of user context through:
6.3.1 Communication Pattern Analysis
Lucia builds comprehensive models of how users communicate across different channels and with different individuals:
Individual communication styles with different contacts
Topic-specific vocabulary and jargon
Temporal patterns in communication frequency
Priority levels for different types of messages
6.3.2 Relationship Mapping
By analyzing communication patterns, Lucia constructs detailed relationship maps that include:
Professional hierarchies and reporting structures
Personal relationship dynamics
Communication preferences for different relationships
Historical context for each relationship
6.3.3 Topic Threading
Lucia maintains continuous understanding of ongoing conversations and projects by:
Tracking discussion threads across multiple channels
Linking related conversations from different time periods
Identifying recurring themes and topics
Maintaining context across communication breaks
6.4 Data Connectivity and API Framework
The system implements a flexible data connectivity architecture that facilitates seamless integration with diverse information sources through standardized application programming interfaces (APIs). This architecture enables bidirectional data flow between the core application and various external platforms, including email service providers, local filesystem resources, instant messaging protocols, and social media platforms. The connectivity layer abstracts the underlying complexity of different data sources through a unified interface, allowing for consistent data handling regardless of the source platform.
6.4.1 Cross Platform Integration
The implementation supports both pull and push mechanisms for data synchronization, with configurable polling intervals for services that don't provide native push notifications. For email integration, the system implements standard protocols including IMAP, POP3, and SMTP, while maintaining separate authentication contexts for each connected account. Local filesystem integration is achieved through a secure file system monitoring service that maintains real-time synchronization with designated directory structures. For messaging platforms such as Telegram and Discord, the system leverages their respective official APIs, implementing websocket connections for real-time message handling and OAuth 2.0 for secure authentication. Social media integration, exemplified by the Twitter (X) platform connection, utilizes REST APIs with rate limiting consideration and proper pagination handling for historical data retrieval.
6.4.2 Extensible API Framework
The system's architecture has been designed with future extensibility as a primary consideration. The connectivity layer implements a plugin-based architecture that allows for the dynamic integration of new data sources without requiring modifications to the core system. This extensibility is achieved through several key components:
Abstract Interface Layer
The system defines a set of abstract interfaces that new data source integrations must implement:
Data Source Interface: Defines standard methods for data retrieval, creation, modification, and deletion operations.
Authentication Interface: Provides a standardized approach to handling various authentication mechanisms.
Event Handler Interface: Enables uniform handling of real-time updates and notifications.
Error Handler Interface: Standardizes error reporting and recovery procedures across different integrations.
Generic REST API Framework
To facilitate third-party integration development, the system includes a comprehensive REST API framework that provides:
Standardized Endpoint Structure
Resource-oriented URL patterns
Consistent query parameter handling
Uniform response formatting
Standardized error reporting
Authentication Mechanisms
Auth 2.0 integration
API key management
JWT token handling
Rate limiting controls
Data Transform Layer
Protocol buffers support
JSON schema validation
Binary data handling
Stream processing capabilities
The implemented architecture provides a robust foundation for current integrations while ensuring straightforward extensibility for future data sources. The planned generic REST API framework and developer tools will further enhance the system's capability to incorporate new data sources through standardized interfaces and comprehensive development support.
7 Privacy-Preserving Inference
The proliferation of large language models (LLMs) has introduced significant privacy concerns regarding the handling of user interactions. Contemporary AI systems typically store user queries and conversations, potentially incorporating them into future training datasets. This practice raises substantial privacy concerns, particularly for applications involving sensitive information in domains such as healthcare, finance, or proprietary business communications. While recent advances in AI capabilities have enabled sophisticated natural language interactions, the underlying architectures frequently prioritize model improvement over user privacy. Lucia introduces a novel architecture for privacy-preserving inference that leverages a network of independent GPU nodes operating under strict security guarantees. We demonstrate that through careful implementation of Trusted Execution Environments (TEEs) and sophisticated attestation protocols, it is possible to provide strong privacy guarantees while maintaining high performance characteristics.
7.1 Introduction to Trusted Execution Environments on modern GPUs
At the heart of Lucia's privacy guarantees lies the implementation of Trusted Execution Environments (TEEs) on modern GPUs. To understand why this is revolutionary, we need to examine how TEE technology works and why it provides such strong privacy guarantees. A TEE creates what we might think of as a secure vault within the GPU itself. When code runs inside this vault:
The surrounding system cannot inspect or modify the running code
The data being processed remains encrypted and protected
Even the GPU's owner cannot access the raw information
The integrity of the computation is cryptographically verified
Recent research on NVIDIA H100 GPUs has demonstrated that TEE implementations can provide these security guarantees with minimal performance impact. Empirical studies show performance overhead of less than 7% for most operations, with larger models experiencing nearly zero overhead. This means we can achieve robust privacy protection without sacrificing the responsiveness users expect from AI systems.
7.2 GPU Node Infrastructure
Our architecture implements a decentralized network of GPU nodes, each operating as an independent inference provider while maintaining strict privacy guarantees through hardware-backed TEE security mechanisms. This TEE implementation was realized in collaboration with Nillion. The operation of nodes is permissionless and accessible to anyone who can meet the system requirements, bandwidth specs and has staked the required amount of $LUCIA token.
7.3 Node Security Implementation
Each node in the network implements several critical security components:
Hardware-backed TEE utilizing the capabilities of modern GPU architectures
Sophisticated attestation protocols for continuous security verification
Secure boot chain ensuring system integrity
Runtime monitoring for security policy enforcement
The TEE implementation provides several security guarantees:
Memory encryption for all processing data
Execution isolation from host system
Verified code execution
Protected data pathways
7.4 Attestation Protocol
We implement a multi-stage attestation protocol that provides continuous verification of node security properties. The protocol operates through several distinct phases:
Initial Attestation:
Hardware identity verification
Security feature validation
Configuration verification
Code integrity checking
Continuous Monitoring:
Real-time integrity validation
Security policy enforcement
Anomaly detection
Performance verification
7.5 Secure Data Flow
The protocol implements several stages of data protection:
Input Processing:
Immediate encryption using ephemeral keys
Secure transmission to TEE
Verified memory allocation
Model Execution:
Protected parameter loading
Secure computation within TEE
Protected intermediate states
Response Generation:
Secure assembly of output
Verified delivery
Complete memory clearing
7.6 Performance Analysis
Recent work by Zhu et al. [1] from Phala Network has demonstrated the feasibility of large model TEE implementation on modern GPUs. Their benchmark results indicate minimal performance impact from the security mechanisms:
Model Size
7B
13B
70B
Overhead (%)
6.85
4.58
0.13
Latency Impact (ms)
0.42
0.31
0.08
Table 1: TEE Performance Benchmark [1] Confidential Computing on nVIDIA H100 GPU: A Performance Benchmark Study. September 16, 2024
7.7 Conclusion
The results demonstrate the feasibility of large-scale inference to preserve privacy while maintaining high performance characteristics. However, it is important to note that not every GPU hardware platform supports the same TEE features. For this reason, only NVIDIA enterprise-class GPUs will initially be used until other manufacturers offer compatible solutions.
Future work will focus on:
Enhanced attestation protocols for improved security guarantees
Reduced performance overhead through optimized TEE implementations
Extended support for diverse GPU architectures
Improved scalability of the node network
These advancements will further strengthen the privacy guarantees while maintaining or improving system performanc
Dual-Key Authentication with Distributed MPC
8.3.1 Data Isolation and Compartmentalization
Lucia’s backend infrastructure utilizes dual-key authentication systems based on Nillion’s Multi-Party Computation (MPC) network. The implementation combines locally-stored keys with distributed MPC network keys. Particular attention is given to threshold signature schemes where one share is maintained locally, offering a balance between security and user sovereignty.
Authentication systems have evolved significantly from simple password-based approaches to sophisticated cryptographic solutions. This chapter explores a novel authentication paradigm that combines the security benefits of distributed systems with the practicality of local key management. The proposed dual-key authentication system leverages MPC networks to enhance security while maintaining user control over authentication processes.
8.1 Non-Interactive MPC Networ
Recent developments in MPC technology, particularly the Nillion Network architecture, have introduced transformative approaches to distributed computation and secure data storage. This architecture implements Non-Interactive Proofs (NIPs) within its MPC framework, enabling parallel processing and minimizing communication overhead between parties. The key innovations include:
1. Parallel Processing: Unlike traditional MPC systems that require synchronous operation, the NIL Network enables parallel computation across network nodes, significantly improving scalability and performance.
2. Non-Interactive Operations: The system performs computations without requiring constant communication between parties, reducing network overhead and improving response times crucial for authentication workflows.
3. Secure Enclaves: Data processing occurs within secure computational environments while maintaining the distributed nature of the system.
4. Optimal Online Phase: By minimizing the communication rounds during user presence, the system achieves optimal latency for authentication operations.
These advancements enable more efficient implementation of dual-key authentication systems by reducing computational overhead and improving scalability. The combination of local key sovereignty with distributed network computation provides robust security while maintaining practical usability.
8.2 Key Component Distribution
The authentication layer is built upon three primary components:
1. Local Key Component (LKC): A cryptographic key stored within the user's trusted personal device. This component ensures user sovereignty over the authentication process and prevents unauthorized access even if the MPC network is compromised.
2. Network Key Component (NKC): A distributed key shared across multiple independent parties within the MPC network. This component is managed through secure MPC protocols, ensuring that no single party can reconstruct the key independently.
3. Trust Assumptions:
- Local user device maintains key confidentiality
- MPC network maintains honest majority
- Communication channels are authenticated and encrypted
8.3 Authentication Flow
The authentication process requires the coordinated use of both key components:
1. Initial Authentication Request
- User initiates authentication with their local key component
- System generates a challenge requiring both key components
2. Dual Signature Generation
- Local device signs with LKC
- MPC network performs distributed signing with NKC
3. Verification
- System combines signatures from both components
- Authentication succeeds only if both signatures are valid
9. Ecosystem Decentralization
A fundamental objective of Lucia's design lies in liberating users from the constraints and value capture imposed by centralized platforms while restoring individual data sovereignty. This principle necessitates establishing a robust framework for comprehensive decentralization, thereby preventing Pindora or any other stakeholders from assuming gatekeeper positions within the ecosystem. The ethical underpinning of this approach manifests in our commitment to systematically decentralizing all components of the ecosystem, effectively precluding Pindora from exercising unilateral control over any aspect of the application architecture.
The implementation of this decentralized architecture not only enhances system resilience but also embodies the principles of digital autonomy and user empowerment that form the foundation of next-generation distributed systems. Through this carefully considered approach, we establish a framework that inherently resists the concentration of control and promotes the democratization of digital infrastructure.
This process begins with a semi-centralized architecture that maintains reliability during initial deployment, followed by systematic decentralization of key components:
9.1 Progressive Decentralization Framework
The decentralization process operates across three primary vectors:
1. Computational Infrastructure Decentralization
Initial deployment utilizes a controlled set of verified GPU nodes
Progressive expansion to include community-operated nodes that meet strict security and
performance requirements
Implementation of reputation systems to evaluate node reliability and performance
Development of automated node selection algorithms based on historical performance
metrics, utilization and latency parameters
Economic responsibility through collateral requirements for node operators
2. Governance Mechanism
Phased implementation of on-chain voting mechanisms
Gradual transfer of decision-making authority to token stakers
Implementation of quadratic voting systems to prevent plutocratic control
Development of proposal review frameworks managed by distributed autonomous organization (DAO)
3. Protocol Development Decentralization
Open-sourcing of core components with documented contribution guidelines
Implementation of community-driven development processes
Creation of technical committees selected by token stakers
Establishment of grant programs for independent developer contributions
9.2 Blockchain Integration Architecture
The system leverages blockchain technology across multiple layers to ensure transparent and verifiable operations:
Smart Contract Layer
Implementation of automated governance execution
Payment of fees for provided computing services
Node reputation tracking and rewards distribution
Buyback and burn mechanism
Automated security deposit management for node operators
Slashing mechanism to punish malicious actors
9.3 Node Infrastructure
The computational framework utilizes a distributed network of GPU-powered nodes with the following specifications:
Dynamic load balancing with real-time resource allocation
Automated scaling protocols for workload management
Integration with Nillion's TEE framework
Real-time monitoring and predictive maintenance systems
Token Economics and Ecosystem Incentives
The landscape of AI agents reveals a concerning trend where major providers implement what we might call "memory handcuffs" – strategies that make it difficult or impossible for users to transfer their conversation history and accumulated knowledge to different platforms. This approach to user lock-in creates several significant problems that affect both individuals and organizations.
10.1 The Role of $LUCIA Token
The $LUCIA utility token serves as the foundational element of Lucia's decentralized ecosystem, carefully designed to align incentives among all participants while enabling sophisticated functionality. Understanding the token's role requires examining how it enables and governs various system capabilities while ensuring sustainable ecosystem growth. The token creates a circular economy where value flows between users, node operators, and the platform itself, fostering a self-sustaining environment that rewards participation and contribution.
10.2 Technical Implementation
The $LUCIA token implements the ERC20 standard on the Base L2 blockchain, providing a robust foundation for diverse functionality. This technical choice offers several advantages:
First, Base's Layer 2 scaling solution enables rapid transaction processing with minimal fees, essential for smooth user experience in features like real-time summaries and interactive spaces. The implementation includes sophisticated smart contracts that handle automatic conversion of fiat payments rails to $LUCIA tokens, making the system accessible to users regardless of their cryptocurrency experience.
Second, the token incorporates a novel 0.5% transaction fee mechanism that automatically contributes to liquidity pools, ensuring stable token value and smooth trading experience. This mechanism implements automated market maker (AMM) principles to maintain efficient token circulation and price discovery.
10.3 Subscription Mode
The subscription system implements tiered access control that verifies token holdings or ongoing subscription payments. This creates three distinct service levels:
Basic Tier provides entry-level access with core functionality, requiring no subscription. This tier allows users to experience Lucia's fundamental capabilities while maintaining a low barrier to entry.
Pro Tier unlocks enhanced capabilities through subscription payments. This tier includes advanced features like connection of personal accounts and LLM selection and priority for inference access.
10.4 Premium Feature Access
The LUCIA token also serves as the gateway to an advanced suite of premium capabilities, available through temporary subscription upgrades. This tokenized access mechanism ensures that users can unlock sophisticated features while participating in the platform's economy.
1
Advanced AI Model Access
Users can access unrestricted AI models that operate with enhanced parameters and reduced constraints, enabling more natural and comprehensive interactions. These models facilitate deeper, more nuanced conversations by operating beyond traditional AI limitations without traditional safeguards.
2
Specialized AI Agent Deployment
Users gain access to a diverse ecosystem of specialized AI agents, each equipped with domain-specific expertise. These multi-model agents can be dynamically activated based on specific use cases, allowing users to leverage targeted capabilities for particular tasks or industries. The system intelligently coordinates these agents to provide comprehensive solutions while maintaining seamless integration.
3
Avatar Personalization Framework
The platform provides extensive customization options for virtual avatars, allowing users to craft unique digital representations. This includes fine-tuning visual attributes, voice characteristics, and behavioral patterns. Users can create avatars that align with their preferences or specific use cases, enhancing the immersive nature of interactions.
This premium feature set, accessible through $LUCIA tokens, creates a comprehensive enhancement layer that significantly expands the platform's capabilities while maintaining a balanced and sustainable economic model.
10.5 Staking Implementation
The $LUCIA token implements a sophisticated staking mechanism that aligns participant incentives while enabling decentralized governance and network security. The staking contract supports multiple functionalities through a carefully designed system of rewards and requirements.
10.6 Staking Architecture
The staking system implements several key mechanisms:
Base Staking Protocol:
Minimum staking period: 14 days
Variable reward rates based on staking duration
Dynamic reward pool allocation
Automated reward distribution
Staking Tiers:
Basic Staker (no min requirements)
Base reward rate
Basic voting rights
Standard feature access
Governance Staker (min. 1,000 USD in $LUCIA tokens)
Enhanced reward rate
Proposal creation rights
Advanced feature access
Priority voting weight
Node Operator (min. 10,000 USD in $LUCIA tokens)
GPU Node participation rights
Advanced feature access
Node operation privileges
10.7 Node Operator Collateral
The $LUCIA token plays a crucial role in maintaining network security. Node operators must maintain substantial stake as collateral to participate in the network:
Security Requirements:
Minimum stake: 10,000 USD in $LUCIA tokens at Node creation date
Lock period: 30 days
Slashing conditions for malicious behavior
Performance monitoring metrics
Slashing Mechanisms:
Inference Violations
1% reduction of the staked collateral if node fails to execute an accepted inference request. This slashing mechanism ensures reliable service delivery and prevents nodes from selectively processing or ignoring user jobs they've committed to handle
No slashing if node is deactivated or not accepting inference requests
Security Violations
TEE Attestation violation: 100% stake reduction
Malicious behavior: 100% stake reduction and permanent blacklisti
10.8 Governance System
The governance mechanism enables decentralized decision-making while ensuring system security and stability. Requirements for proposal submission:
Minimum stake: 1,000 USD in $LUCIA tokens
Stake lock during proposal period
Detailed proposal documentation
Clear implementation timeline
Proposal Types:
Technical Proposals
Protocol modifications
Feature additions
Security updates
Performance improvements
Economic Proposals
Reward rate adjustments
Fee structure changes
Treasury allocations
Token burns
Administrative Proposals
Governance process updates
Parameter adjustments
Role definitions
Policy changes
10.9 Voting Mechanism
The voting system implements sophisticated weighting and security measures:
Vote Weight Calculation:
Vote_Weight = Base_Stake * Time_Multiplier * Participation_Factor\
Where:
Base_Stake: Number of staked tokens
Time_Multiplier: Increases with staking duration
Participation_Factor: Based on historical governance participation
Voting Process:
1. Proposal Review Period (7 days)
Community discussion
Technical analysis
Impact assessment
Refinement opportunities
2. Voting Period (14 days)
Active stake voting
Vote weight calculation
Real-time tallying
Result verification
3. Implementation Period
Technical preparation
Gradual rollout
Performance monitoring
Feedback collection
10.10 Initial Token Distribution
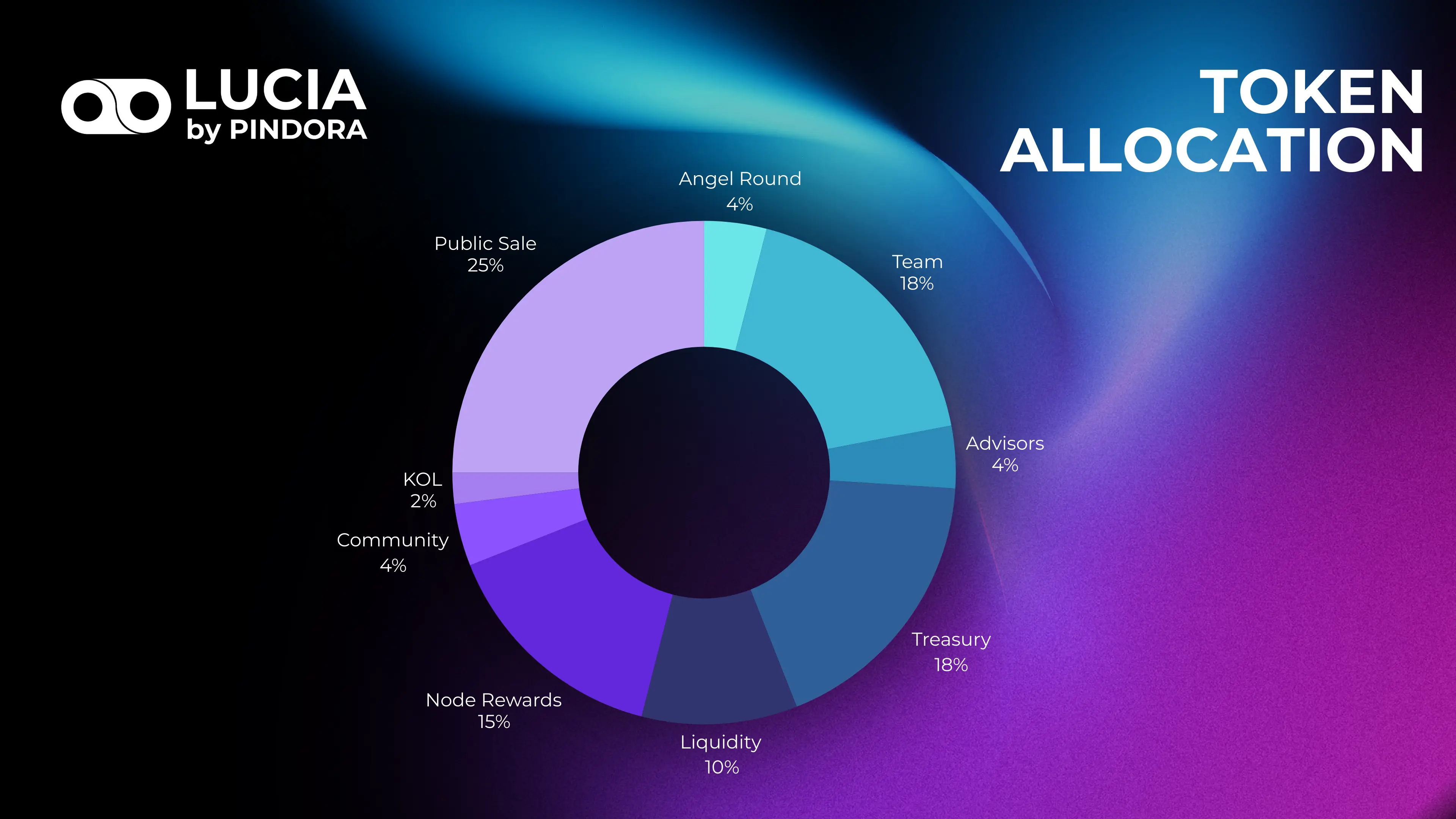
Figure 2: $LUCIA Token Allocations
Initial supply is fixed at 1 billion tokens, with no future minting capability. This creates a predictable supply framework that prevents inflation while maintaining sufficient liquidity for system operation. Distribution follows a carefully designed allocation strategy that balances immediate utility with long-term growth:
Community Development: Supporting user adoption and engagement
Protocol Development: Ensuring continued technical advancement
Strategic Partnerships: Enabling ecosystem growth
Liquidity Provision: Maintaining market efficiency
Node Rewards: Token incentives to bootstrap the initial GPU resources
10.11 Revenue Distribution Model
The service fee structure for premium features implements a carefully designed distribution mechanism that balances stakeholder incentives while ensuring sustainable ecosystem growth.
The distribution framework consists of four primary allocation channels:
Node Provider Compensation (70%)
The majority share of service fees is allocated to GPU node providers, recognizing their essential role in maintaining the network's computational infrastructure. This substantial portion incentivizes continued participation and investment in high-quality computing resources, ensuring the network's capacity to meet growing demand.
Protocol Treasury (10%)
A dedicated portion of all service fees is directed to the protocol treasury, which operates under decentralized governance mechanisms. This allocation serves as a sustainable funding source for ongoing protocol development, ecosystem improvements, and strategic initiatives. The treasury's management through community governance ensures transparent and aligned decision-making for resource allocation.
Staking Pool Contributions (10%)
To promote network security and stakeholder participation, one-tenth of service fees are automatically deposited into the protocol's staking pool. This mechanism enhances network stability while providing additional yield opportunities for token holders who actively participate in the governance process of the network.
Deflationary Mechanics (10%)
The final portion of service fees is systematically allocated to a buy-back-and-burn mechanism. This deflationary approach reduces the total token supply over time, potentially enhancing token value while creating a sustainable economic model. The burning process is executed automatically through smart contracts, ensuring transparency and predictability in supply dynamics.
This distribution model creates a self-reinforcing ecosystem that aligns incentives across all participant categories while maintaining long-term sustainability through carefully balanced economic mechanisms.
Implementation Roadmap
11.1 Phase I: Core Development (Q1-Q4 2024)
The foundational phase established the critical infrastructure necessary for subsequent development. During this period, the team focused on implementing the core AI architecture, integrating essential communication protocols, and establishing a secure cloud processing framework. This phase also encompasses the development of the tokenomics framework for the $LUCIA utility token, laying the groundwork for the platform's economic model.
11.2 Phase II: Alpha Release and Token Generation (Q1 2025)
The initial public implementation marks a crucial milestone in Lucia's development. This phase introduces the alpha version with core functionality, particularly emphasizing integration with Telegram and Discord protocols and local files upload. The token generation event (TGE) occurs during this period, accompanied by the establishment of comprehensive feedback mechanisms for continuous system optimization.
11.3 Phase III: Security Layer Implementation (Q2-Q3 2025)
Security takes center stage in the third phase, with the deployment of sophisticated encryption standards for both data at rest and in transit. The implementation of a zero-trust architecture, combined with third-party security audits and robust vulnerability management systems, ensures the highest level of data protection and system integrity.
11.4 Phase IV: Computational Infrastructure (Q3 2025-Q4 2025)
The focus shifts to enhancing processing capabilities through the implementation of dynamic load-balancing mechanisms and comprehensive monitoring systems. This phase includes crucial integration with Nillion's Trusted Execution Environment (TEE) framework and the development of automated node scaling protocols, ensuring optimal performance and scalability.
11.5 Phase V: Feature Enhancement (Q1-Q2 2026)
Advanced feature implementation characterizes this phase, including integration of cross-platform unified data synthesis. The implementation of sophisticated sentiment analysis algorithms and enhanced token utility mechanisms further expands the platform's capabilities.
11.6 Phase VI: Marketplace Launch (Q3 2026-Q4 2026)
The final implementation phase introduces a marketplace for third party expert AI agents, advanced analytics frameworks, and expanded token utility features, preparing the platform for mass deployment.
11.7 Phase VII: Ecosystem Expansion (Q1 2027+)
Continuous development focuses on expanding the ecosystem through the release of open source developer SDKs and implementation of additional platform protocols. This phase emphasizes long-term growth and adaptation to emerging technological advances.
12. Future Outlook of Autonomous Agents
12.1 The Coming Information Cascade
We stand at the threshold of a fundamental transformation in how information flows through society. The widespread adoption of AI agents across all sectors of the economy will create an unprecedented surge in digital communication that will far exceed human processing capabilities. To understand the magnitude of this shift, consider how current communication patterns will evolve when AI agents become ubiquitous.
Today, a business might receive dozens or hundreds of emails, calls, and messages daily. In the emerging AI-driven landscape, this same business could face thousands or even millions of inquiries from autonomous agents representing various stakeholders, customers, partners, and competitors. These agents will operate continuously, generating requests, proposals, and interactions at a pace that would overwhelm any human team.
For individual consumers, the situation becomes equally challenging. Imagine waking up to hundreds of personalized offers, each generated by sophisticated AI agents that have analyzed your preferences, behaviors, and needs. These agents will be far more capable than current automated systems, able to engage in natural conversation, negotiate terms, and adapt their approach based on your responses. The traditional concept of "spam filters" becomes inadequate when facing AI agents that can craft perfectly personalized, seemingly relevant messages at scale.
12.2 Human Bandwidth Challenge
The fundamental challenge lies in the asymmetry between human and AI communication capabilities. While humans are limited by cognitive constraints and the need for sleep, AI agents can: 1. Process information at speeds millions of times faster than human comprehension 2. Engage in thousands of simultaneous conversations 3. Analyze vast amounts of data in real-time 4. Operate continuously without breaks or downtime This creates what we might call the "AI communication paradox": as AI agents become more sophisticated at reaching us, they collectively make it impossible for us to meaningfully engage with any of them. The very technology that promises to make communication more efficient threatens to render it overwhelming.
12.3 The Personal AI Guardian
The solution to this communication cascade lies in fighting fire with fire – or more precisely, AI with AI. Every individual and organization will need their own AI agent that serves as an intelligent intermediary between them and the growing ecosystem of autonomous agents. Lucia represents an early implementation of this concept, designed to handle the coming wave of AI-driven communication.
12.4 Core Functions of Personal AI Guardians
These personal AI agents will perform several critical functions:
Information Filtering: The agent must analyze incoming communications across all channels, distinguishing between:
Truly important messages requiring human attention
Routine matters that can be handled autonomously
Sophisticated spam attempting to bypass traditional filters
Legitimate but low-priority communications
Autonomous Negotiation: Personal AI agents will conduct initial negotiations with other agents, handling:
Preliminary business discussions
Service inquiries and quotes
Schedule coordination
Basic contract terms
Information Synthesis: Rather than simply filtering information, these agents will:
Aggregate related communications
Identify important patterns and trends
Summarize complex interactions
Present insights in human-digestible formats
12.5 The New Communication Hierarchy
This evolution will create a new hierarchy of digital communication:
Level 1: AI-to-AI Communication
High-bandwidth, continuous interaction between autonomous agents
Sophisticated protocols for negotiation and information exchange
Real-time adaptation and learning
Formal verification of intentions and capabilities
Level 2: AI-to-Human Communication
Filtered, synthesized information delivery
Contextual summaries and recommendations
Priority-based attention routing
Interactive clarification and feedback
Level 3: Human-to-Human Communication
Enhanced by AI understanding and context
Supported by autonomous background processes
Enriched with relevant insights
13 Conclusion: Shaping the Future of Human-AI Interaction
As we stand at the threshold of an era defined by ubiquitous AI systems, the need for privacy-preserving, user-centric approaches to artificial intelligence becomes increasingly critical. Throughout this paper, we introduced Lucia as a fundamental solution for how humans and artificial intelligence can interact in a world where privacy and data sovereignty are paramount.
The technical innovations described in this paper – from our sophisticated vector database implementation to our groundbreaking infinite memory architecture – serve a deeper purpose beyond their immediate functionality. They demonstrate that it is possible to build AI systems that respect user privacy without sacrificing capability or performance. Our implementation of Trusted Execution Environments for GPU computation, combined with our decentralized secure inference network, proves that privacy and powerful AI capabilities are not mutually exclusive.
Perhaps most importantly, Lucia's architecture anticipates and addresses the coming challenges of an AI-saturated world. As we have discussed, the proliferation of AI agents will soon create an information density that exceeds human processing capabilities by orders of magnitude. By implementing sophisticated agent-to-agent communication protocols and privacy-preserving interaction frameworks, Lucia provides a glimpse of how humans can maintain agency and control in this emerging landscape
The decision to implement the $LUCIA token as a foundational element of our system reflects our commitment to creating a truly decentralized, community-driven ecosystem. By aligning incentives among users, node operators, and developers, we establish a framework for sustainable growth and continuous innovation. The token's utility extends beyond simple transactions, enabling sophisticated governance mechanisms and ensuring that the platform's evolution remains guided by its community.
Looking ahead, we see Lucia as a crucial step toward a future where AI assistants serve as trusted intermediaries, helping users navigate an increasingly complex digital world while maintaining complete control over their data and digital interactions.
Yet perhaps the most significant aspect of Lucia lies not in its technical capabilities, but in what it represents: a proof that we can build AI systems that enhance human capability while respecting human privacy and autonomy. As AI continues to evolve and permeate every aspect of our lives, this balance between capability and privacy will become increasingly crucial.
We invite researchers, developers, and users to join us in this journey. The frameworks and protocols we have described are designed to be extended and enhanced by the community. Through collaborative effort and continued innovation, we can ensure that the future of AI remains aligned with human values and interests, creating systems that augment human capability while preserving human values.

Copyright: 2024 Lucia by Pindora, www.pindora.io